JavaScript는 어떻게 컴파일될까?
2022.12.26


이미지 출처 : Growtika
먼저, 자바스크립트란 무엇일까?
자바스크립트는 '웹페이지에 생동감을 불어넣기 위해' 만들어진 프로그래밍 언어이다.
자바스크립트로 작성한 프로그램을 script라고 하는데, 이 script는 웹페이지의 HTML안에 작성할 수 있으며, 웹페이지를 불러오면 script가 자동으로 실행된다.
구체적으로는, HTML이 파싱될때 <script>를 만나면 파싱이 중단되고, script를 해석하고 실행한다. 이 해석하고 실행되는 과정을 이 글에서 구체적으로 서술하고 있다.
자바스크립트는 브라우저뿐만 아니라 서버에서도 실행가능하다. JavaScript Engine이라고 불리는 프로그램이 들어있는 디바이스라면 모두 동작한다.
특히 브라우저에는 자바스크립트 가상 머신이라고 불리는 자바스크립트 엔진이 들어가 있다. 이 엔진의 종류는 다양하며, 각 엔진마다 특유의 코드네임이 존재한다.
가장 유명한 V8은 크롬과 오페라에서 사용되며, SpiderMonkey는 파이어폭스, ChakraCore는 마이크로소프트 엣지, SquirrelFish는 사파리에서 사용된다.
이러한 엔진의 동작 원리는 매우 복잡하다. 따라서 먼저 매우 간단하게 이야기해보면 다음과 같다.
- 엔진(브라우저라면 내장엔진)이 스크립트를 읽는다. (파싱)
- 읽어들인 스크립트를 기계어로 전환한다. (컴파일)
- 기계어로 전환된 코드가 실행된다. 기계어로 전환되었기 때문에 실행속도가 빠르다. (실행)
엔진은 프로세스의 각 단계마다 최적화를 진행한다. 예를들어, 컴파일이 끝난 후 실행중인 코드를 감시하면서 이 코드로 흘러가는 데이터를 분석하고 분석결과를 토대로 기계어로 전환된 코드를 다시 최적화하기도 한다. 이런 과정을 거치면 스크립트 실행 속도는 더욱 빨라지게 된다.
과연 자바스크립트 엔진은 어떻게 컴파일하고 실행하며, 최적화를 수행하는 것일까? 이 글에서는 엔진의 컴파일에 대해서 알아보고, 엔진의 최적화는 다음 글로 이어서 작성할 예정이다.
먼저 컴파일 과정에 대해 알아보기 전에, 헷갈릴 수 있는 용어부터 정리하겠다.(본인이 매우 헷갈림)
용어 정리
컴파일
프로그래밍 언어(소��스코드)를 기게어 혹은 기계어와 유사한 low level까지 해석하는 과정이다.
프로그래머가 작성하는 소스코드는 컴퓨터가 이해할 수 없다. 컴퓨터는 0과 1로 이루어진 기계어만 이해할 수 있기 때문에 작성한 소스코드를 기계어로 번역하는 컴파일 과정이 필요하다.
소스코드는 컴파일을 통해 기계어로 이루어진 실행파일이 된다. 이 파일을 실행하면 실행파일 내용이 운영체제를 통해 메모리에 적재되어 프로그램이 실행된다.
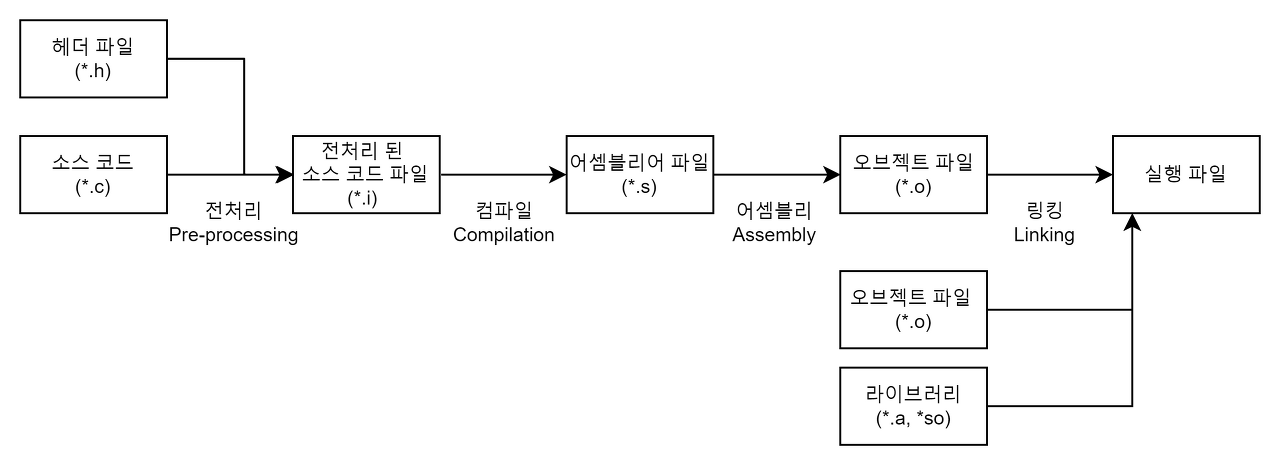
컴파일 과정은 여러 단계로 나누어진다. 이 모든 단계를 통틀어서 컴파일, 빌드라고 부르기도 하며 컴파일과 링킹 과정을 따로 나눠서 부르기도 한다. 보통 빌드는 컴파일보다 넓은 의미(빌드 = 컴파일 + 링킹)으로 사용되는데, 상황에 맞게 적절히 이해하는 것이 좋을 것 같다. (즉 소스코드를 중간코드로 번역하는 과정을 컴파일이라고도 하며, 소스코드가 기게어로 번역되는 전체 과정을 컴파일 과정이라고도 부르는 것 같다.)
컴파일러
프로그래밍 언어를 기계어로 빠르게 컴파일할 수 있도록 미리 번역해둔 프로그램
object code
컴파일러나 어셈블러에 의해 생성된 파일
기계어나 기계어 수준의 바이너리 코드로 해석된 코드를 의미한다.
바이트 코드
가상머신이 이해할 수 있는 중간 레벨로 컴파일 한 코드 (JavaScript에서 가상머신은 브라우저와 node에서 사용되는 V8등을 의미한다.)
VM에서 사용되는 코드 개념으로, 어셈블리어와 유사한 형태를 띄고있다. 컴파일러에 의해 바이트 코드로 변환되고, 이 바이트 코드는 다시 기계어로 해석되는데 이 과정은 인터프리터 방식으로 작동한다.
프로그래밍 언어 -> 컴파일러 -> 바이트 코드(VM이 이해할 수 있는 어셈블리어와 유사한 형태의 저수준 언어) -> 인터프리터 방식으로 기계어로 번역되어 최종 실행
바이너리 코드
컴파일러에 의해 생성된 object code가 바이너리 코드라고 이해하면 쉽다.
바이너리 코드는 컴퓨터가 이해할 수 있는 언어이지만, 링커에 의해 메모리 주소값을 반영하고 CPU가 직접 해독하고 실행할 수 있도록 수정되어야 기계어가 되는 것이기 때문에 가장 기계어와 유사한 레벨의 코드지만 완전한 기계어는 아니다. (목적파일은 바로 실행될 수 없다. 코드가 여러 파일로 나눠져있기 때문에 이 파일들을 연결시키는 과정이 필요하고, 목적파일들을 하나로 통합시켜 하나의 실행파일로 만들기 위해 링크과정이 필요하다.)
어셈블리어
니모닉 기호(mnemonic symbol)을 정해 사람이 쉽게 제어할 수 있도록 한 것으로 기계어에 일대일 대응된다.
컴퓨터는 0과 1만 이해할 수 있는데, 이렇게 0과 1이 나열된 명령어는 이해하기 너무 어렵다. 따라서 사람이 쉽게 기억하기 위해 기계어와 일대일 대응한 것이 니모닉 기호이다. 이 니모닉 기호를 정하여 일련의 명령어를 나타낸 것이 어셈블리어이다.
기계어 (machine code)
CPU가 직접 해독하고 실행할 수 있는 비트 안뒤(0과 1)로 쓰인 컴퓨터 언어
가장 저수준 언어이다. CPU의 종류에 따라 서로 다른 코드를 갖게 된다.
인터프리터
프로그래밍 언어를 한 줄 씩 읽어서 실행하는 프로그램
런타임환경에서 기계어로 바로 번역해서 실행하는 역할을 한다.
JIT 컴파일러
Just In Time, 실시간(런타임) 컴파일 기법
JTIC는 프로그램을 실행하는 시점에 바이트코드를 기계어로 번역하는 역할을 한다. 바이트코드에서 번역된 기계어는 캐시에 저장되어 있기 때문에 재사용시 다시 번역할 필요가 없다. 또한 반복되는 코드가 들어올 때 인터프리터가 다시 기계어로 번역하는 과정과는 다르게 이미 번역된것을 사용하면 되므로 해당시간이 단축된다.
hotspot
코드 중 자주 반복되어서 실행되는 부분
이 부분이 얼마나 빠르게 실행되는가에 의해 성능이 좌우된다.
Compiler vs Interpreter vs JIT
컴파일의 종류에는 3가지가 존재한다.
실행중에 코드를 한 줄 씩 읽어가면서 바로 실행하는 인터프리터 방식과, 실행 전에 컴파일하는 정적 컴파일 방식, 그리고 JITC가 있다. JITC는 동적 번역이라고도 불리며, 실행하는 시점에 바이트 코드를 기계어로 번역하는 컴파일 기법이다.
소스코드 -> 인터프리터 -> 실행 소스코드 -> 컴파일러 -> 실행파일(기계어) -> 실행
인터프리터 언어에는 JavaScript, HTML, python, Ruby등의 스크립트 언어가 있으며, 정적 컴파일 언어에는 자료형이 고정되어 있는 JAVA, C 등이 있다.
컴파일러와 인터프리터의 차이
프로그래머는 고수준언어로 프로그램을 작성하지만, 컴퓨터는 이를 이해할 수 없기 때문에 컴퓨터가 이해할 수 있는 언어로 변환하는 과정이 필요하다. 이를 컴파일러와 인터프리터가 수행한다. 따라서 둘은 동일한 기능을 수행한다. 차이점은 코드를 실행하는 방법이다.
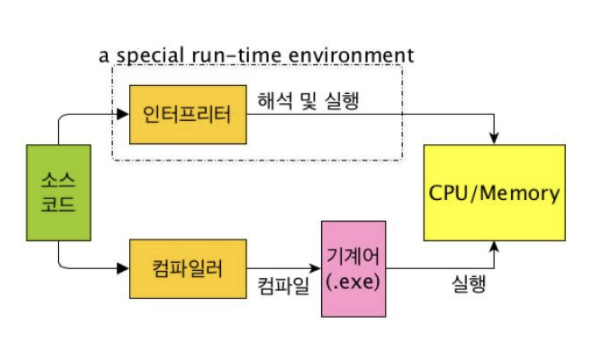
인터프리터의 경우 코드가 번역된 후 컴퓨터로 전달되어 바로 실행된다. 반면 컴파일러는 코드를 실행하지 않으며, 디스크에 번역이 완료된 코드를 저장한다. 저장된 코드는 언제든 실행될 수 있다.
이러한 차이점으로 인해, 인터프리터는 프로그램을 실행할때 필요하므로, 프로그램을 실행시키기 위해서는 반드시 인터프리터가 설치되어 있어야 한다. 반면 컴파일러의 경우는 다르다. 프로그램이 한번 컴파일 되었다면, 컴파일 된 프로그램만 있으면 실행이 가능하므��로 컴파일러나 원본 소스코드는 필요없게 된다.
따라서 인터프리터의 장점은 다른 운영체제의 컴퓨터에서도 실행할 수 있다는 점이다. 프로그램을 컴파일할때에는 지정된 운영체제에 따라 컴파일되며, 따라서 다른 운영체제에서는 동작하지 않는다. 다른 운영체제에서도 실행하기 위해서는 그 운영체제에 따라 재컴파일해야한다. 하지만 컴파일러는 컴파일된 프로그램이 더 효과적으로 수행되도록 운영체제의 사양에 맞게 최적화할 수 있다는 이점이 있다.
반면 인터프리터의 단점은 오버헤드가 가해진다는 점이다. 인터프리터는 실행 중에 코드의 각 줄이 해석되어야 하지만, 컴파일러로 컴파일된 프로그램은 운영체제가 바로 읽고 실행할 수 있다. 당연히 해석하는 추가적인 단계가 존재하는 코드가, 컴파일된 코드보다 느리게 실행된다.
따라서 인터프리터는 이식성에 장점이 있으며, 컴파일러는 성능에 장점이 있다. 컴파일된 프로그램은 운영체제에 따라 최적화할 수 있으며, 이미 해석된 코드를 바로 실행하므로 빠르게 동작한다. 반면 인터프리터는 코드를 바로 실행하므로 해석하는 과정이 필요하다. 따라서 컴파일된 코드보다 느리게 동작하지만, 운영체제에 관계없이 실행가능하다.
하지만... 인터프리터가 실제로 작업을 실행하는 방식에는 몇가지 형태가 있다.
- 프로그램 소스코드를 직접 실행
- 소스코드를 중간코드로 번역한 후 이를 실행
- 미리 컴파일된 코드(인터프리터 시스템의 일부인 컴파일러에 의해 생성되고 저장된 코드)를 수행
컴파일러처럼 인터프리터들은 코드를 번역할 수 있는 능력을 가지고 있다. 하지만 인터프��리터의 명백한 단점은 한 번 코드가 interpret되면, 프로그램이 단순히 코드를 컴파일하는것보다 반드시 느리게 동작할 수 밖에 없다는 점이다. 그러나 이를 컴파일하고 실행하는것보다는 코드를 해석하는데 더 적은 시간이 소요된다.
이 부분이 잘 이해가 안되어서 좀 더 찾아보았다.(참고 : https://bentist.tistory.com/41)
일단 인터프리터 방식도 내부적으로 소스코드를 기계가 이해할 수 있는 형태로 변환이 되어야 한다. 하지만 컴파일러와 다른 점은 전체 소스코드를 한번에 변환하는게 아니라 코드를 한 줄 씩 읽어들여 중간코드나 기계어로 변환해서 임시파일에 저장하고, 변환한것을 바로 실행한다는 점이다.
인터프리터는 기계어로 변환된 코드를 실행파일로 작성하지 않고, 메모리에 로드시켜 실행한다.
따라서, 인터프리터는 소스코드 한 줄을 번역해서 바로 실행하기 때문에, 프로그램이 단순히 전체 코드를 컴파일한 것을 실행하는 것 보단 반드시 느리게 동작할 수 밖에 없다. 그러나 코드 전체를 컴파일하는 시간이 필요하므로 인터프리터가 실행시작시간은 빠르며, 전체 실행 속도는 컴파일러가 훨씬 빠르다는 것을 의미하고 있는 것 같다.
따라서 컴파일러의 경우 실행 속도가 빠르지만, 전체 코드를 컴파일한 후에 에러를 확인할 수 있으므로 디버깅이 불편하다. 수정사항이 발생하면 전체 코드를 다시 컴파일해야한다.
반면 인터프리터는 해석과 실행을 동시에 수행하므로 실행 속도는 느리다. 하지만 한 줄 씩 실행할때마다 에러를 확인할 수 있으므로 실시간 코드 수정이 가능하다.
JIT vs 인터프리터
동적 컴파일이라고도 불리는 JIT는 컴퓨터 프로그램의 런타임 성능을 개선하기 위해서 사용되는 기술이다.
JIT는 인터프리터와 정적 컴파일을 혼합한 방식으로 생각할 수 있다. 프로그램 실행 시점에서 인터프리터 방식으로 기계어 코드를 생성하면서 그 코드를 캐싱하여, 같은 함수가 여러번 불릴때마다 매번 기계어 코드를 생성하는 것을 방지한다.
좀 더 구체적으로 말하면, 실행시점에 바이트 코드(VM이 실행할 수 있는 기계어로 CPU가 읽을 수 있는 기계어와는 다르다)를 기계어로 번역하는 역할을 한다. 바이트코드에서 번역된 기계어는 캐시에 저장되기 때문에 재사용시 다시 번역할 필요가 없다. 또한 코드가 반복된다면 다시 번역하는 과정 없이 재사용할 수 있으므로 시간이 단축된다.
따라서 인터프리터처럼 JIT는 번역된 코드 블럭의 캐싱을 통해 성능을 개선할 수 있다. 또한 정적 컴파일처럼 JIT는 최적화할 수 있는 방법이 있다면 재컴파일을 할 수 있다.
실제로 자바 가상 머신과 V8에서 JIT를 사용한다. 자바 컴파일러가 자바 소스코드를 바이트코드로 변환한 다음, 실제 바이트코드를 실행하는 시점에서 자바 VM이 바이트 코드를 JIT 컴파일을 통해 기계어로 변환한다.
JIT는 인터프리터 방식보다는 빠르며 정적 컴파일 방식보다는 느리지만, 정적컴파일 방식에 비해 이점도 있다. 실행환경에 맞추어 생성된 코드의 선택 및 최적화를 할 수 있다는 점이다. (정적 컴파일은 실행전에 이루어지므로 불가능하다.)
동적 컴파일은 정적컴파일의 단점(실행환경이 바뀌면 동작된다는 보장이 없음)을 보완한다. 실행 시 컴파일하기 때문에 실행환경에 따라 동작을 보장할 수 있으며, 컴파일을 환경에 맞게 최적화할 수 있다. 하지만 이러한 특징으로 인해 컴파일된 내용을 메모리에 상주시켜야하므로 메모리 사용량이 늘어난다. 또한 수행 시 컴파일을 병행하므로 실행지연이 발생한다. 이러한 단점을 보완하기 위해 적응형 컴파일이 등장했다.
Adaptive Compilation
실행초기에는 인터프리터로 실행하고, 자주 호출되는 메소드나 반복되는 코드를 검출하여 이런 코드만 컴파일하는 방식
JIT 컴파일러의 단점을 보완하기 위한 방식으로, 코드가 사용되었을때 즉시 컴파일하는 것이 아니라, 여러번 호출 된 후 지연시켜 컴파일을 수행하는데 이를 Lazy Compilation이라 한다.
일반적으로 프로그램이 실행될때, 실행시간의 대부분은 프로그램의 극히 일부에서 소비된다는 말이 있다. (80/20 법칙. 참고 : https://jangsunjin.tistory.com/182)
이처럼 adaptive 컴파일에서는 실행시간의 대부분을 소비하는 코드만 컴파일하여 효율적으로 실행속도를 향상시킬 수 있다. 적응형 컴파일에 의한 최적화는 정적 컴파일에서는 얻을 수 없는 정보를 바탕으로 최적화를 지원하기 때문에 오히려 정적컴파일보다 성능이 향상되는 경우도 있다.
JavaScript 엔진
1. 소스코드 -> 바이트 코드
이제 자바스크립트로 돌아와, 자바스크립트에서는 어떤 컴파일 방식을 사용하는지 알아보자.
자바스크립트는 기본적으로 text형식이기 때문에, 코드를 실행하기 전에 해석하는 컴파일 과정이 필요하다. 먼저 소스코드를 파싱하여 중간언어(IR)인 바이트코드 형태로 변환한다.
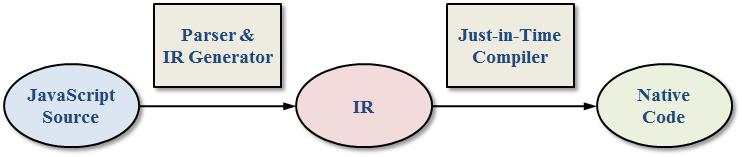
이 바이트 코드로 변환하는 과정도 세부 단계로 이루어져있는 듯 하다. JavaScript 소스코드를 바이트 코드로 변환하는 단계를 더 세부적으로 나타내면 다음과 같다.
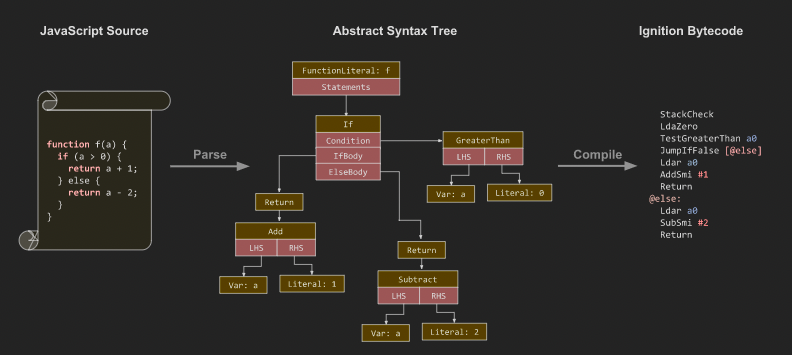
- 코드를 의미있는 조각으로 나누는 렉싱/토크나이징 (이때 스코프가 결정되므로 자바스크립트는 렉시컬스코프를 가지게 된다.)
- 코드를 트리구조로 나타내는 AST로 만드는 파싱
- VM이 실행할 수 있도록 AST를 바이트코드로 변환하는 컴파일
여기서 AST를 바이트 코드로 변환하는 것은 Ignition이라는 인터프리터이다. 인터프리터가 바이트코드로 해석하는것을 컴파일이라고 나타내고 있다.
2. 바이트 코드 -> 실행
Ignition이 만든 바이트코드를 실행함으로써 자바스크립트 코드가 동작된다.
이때 인터프리터 모드라면 바이트코드를 하나씩 읽어가며 동작을 수행하고, JIT 모드라면 생성된 바이트코드를 기반으로 native code(기계어)로 컴파일하여 수행하게 된다.
당연히 인터프리터로 코드를 한 줄씩 바로 번역해서 실행하는것보다는 native code로 미리 번역해둔것을 수행하는게 더 빠르다. 하지만... JavaScript에서는 그렇다고 할 수 없다.🤔
정적 컴파일러라면 기계어를 생성하는 도중에 많은 최적화 알고리즘을 사용할 수 있어서 code quality가 높지만, JIT는 컴파일 과정 자체가 실행중에 발생하기 때문에 이 자체가 오버헤드가 되고, 따라서 컴파일에 많은 시간을 쓸 수 없다.
따라서 코드 전체를 읽어서 최적화하는 방식은 당연히 사용할 수 없고, 보통 아주 최소한의 최적화만 적용하여 native code를 생성한다. 이래도 인터프리터 수행시간보다는 native code의 수행 성능이 훨씬 낫다. 따라서 JIT에 오버헤드가 포함되더라도 인터프리터보다 빠르게 수행되므로 Java VM에서는 JIT를 많이 사용한다.
JavaScript에서는 어떨까?
JavaScript는 Java와 달리 동적 타입 언어이다. 변수의 타입이 실행중에 달라질 수 있고, 프로토타입 기반 방식을 사용하는 등 매우 동적 언어이기 때문에 JavaScript JIT 컴파일러는 모든 예외적인 케이스를 다 고려하여 코드를 생성해야한다.
예시로, 단순히 변수 두개를 더하는 코드를 생각해보자. 이때에도 모든 예외케이스를 고려하면 �상당히 많은 양의 native code가 생성된다.
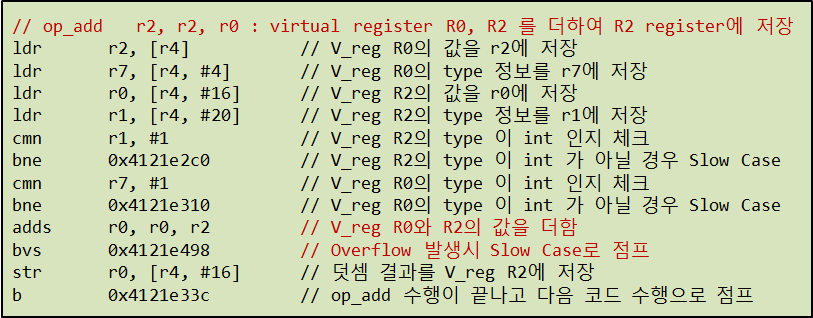
두 변수가 모두 int형일 경우 / 하나라도 int형이 아닐 경우 / 더하고 나니 integer 범위를 벗어나는 등 많은 예외 케이스가 존재한다.
이렇게 예외케이스가 발생하게 되면 slow case로 점프하게 된다.
- slow case : native code로 생성하기 어려운(native code로 표현하면 양이 많아지는) 동작들을 native code로 뽑아내는 대신 미리 엔진 내부에 C로 구현된 helper function을 호출하여 동작을 수행하는 경우를 의미한다.
만약 slow case로 넘어가지 않고 이러한 예외 케이스들을 모두 native code로 작성한다면 int+int, string+string, string+int등의 이런 케이스들을 모두 native code로 작성해야하고, 엄청나게 길어지게 될것이다...
그런데 이런 helper function들은 인터프리터 모드로 수행할때와 동일한 코드를 사용하게 된다...😲 즉, JIT 컴파일러로 native code를 수행한다 해도 많은 부분이 인터프리터를 사용할때와 차이가 없게 되는 것이다!! 오히려 컴파일 오버헤드(native code를 생성해야하는)가 더해지므로 JavaScript에서 JIT는 Java에서보다 훨씬 비효율적이다.
또다른 문제도 존재한다. JavaScript로 구현되는 프로그램들의 특성은 Java와 상당히 다르다. Java는 연산이 많은 프로그램들이 많은 반면, JavaScript는 주로 웹페이지의 layout을 건드리거나 사용자 입력에 반응하는 방식의 프로그램이 많다. 두가지의 큰 차이점은 자주 반복되어서 수행되는 구간(hotspot)의 양인데, JavaScript는 상대적으로 hotspot이 매우 적다.
이 경우 native code를 수행하는 시간에 비해, native code를 만드는 시간, 즉 �컴파일 오버헤드가 상대적으로 커지게 되는 문제가 있다. 결과적으로 컴파일 오버헤드 + 네이티브 코드가 인터프리터보다 빠르다라는 JIT의 사용이유가 무의미해진다. (실제 JavaScript JIT가 성능 향상에 기여하는 바가 거의 없다는 연구도 진행된 바 있다고 한다.)
요약 ) JIT는 정적컴파일에 비해 최적화를 많이 할 수 없어서 정적컴파일보다 느리다. 하지만 그래도 인터프리터보다 빠르기 때문에 자바에서는 JIT를 사용하는데, JavaScript는 동적언어라는 점 + hotspot이 적다는 특성때문에 JIT가 인터프리터보다 빠르다고 할 수 없다.
결국 hotspot이 많이 없는 JavaScript 코드는 인터프리터로 수행하는 것이 낫다.
하지만!! 최근에는 JavaScript가 단순히 웹에서 이벤트 처리 용도로만 사용되는 것이 아니라 그 사용용도가 다양해지면서 점차 연산이 많아지는 프로그램에도 충분히 사용되기 때문에, JIT를 완전히 버릴 수 없다고 한다.
그렇다면 고전적인 방식의 JavaScript코드(hotspot이 많이 없는)와 연산 중심의 코드들의 수행 성능을 모두 만족시키는 방식은 없을까?
JavaScript 엔진 - Adaptive JIT
드디어...! 최근 JavaScript 엔진들은 대부분 adaptive compilation 방식을 사용하고 있다고 한다.
adaptive compilation이란, 모든 코드에 일괄적으로 같은 수준의 최적화를 적용하는것이 아니라, 반복 수행되는 정도에 따라 유동적으로 서로 다른 최적화 수준을 적용하는 방식이다.
기본적으로 모든 코드는 처음에 인터프리터로 해석한다. 그러다가 자주 반복되는 부분(hotspot)이 발견되면, 그 부분에 대해서만 JIT를 적용하여 native code로 변환한다.
최근의 엔진들은 JIT 역시 여러 단계로 나누어서 수행한다. 처음에는 최소한의 최적화만 적용하는 JIT(baseline-JITC) 로 컴파일하여 수행하다가, 더 자주 반복되는 코드에는 더 많은 최적화를 적용하는 JIT(Optimizing-JITC) 로 컴파일하여 code quality가 높은 코드를 생성하게 된다.
- Hotspot이 별로 없는 고전적인 JavaScript 프로그램들에는 interpreter가 JITC보다 효율이 좋다.
- 최근 많이 사용되는 compute-intensive한 JavaScript 프로그램들에는 JITC가 좋다.
- 두 가지 성향의 코드에 대한 성능을 모두 만족하기 위해 최근 엔진들은 adaptive JITC를 채용한다.
- Adaptive JITC는 type profiling을 수행하므로, 변수의 type이 변하지 않는다면 높은 성능을 얻을 수 있다.
실제 V8 엔진의 adaptive JITC인 crankshaft의 동작 방식이 아래와 같다.(Crankshaft는 interpreter가 없고 baseline JITC부터 시작한다.)
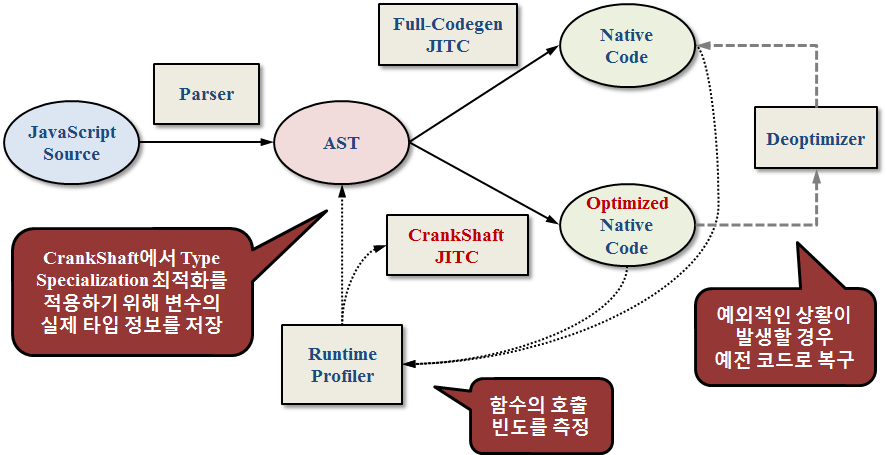
공통적으로 adaptive JITC를 사용하는 엔진은 runtime profiler에서 함수의 수행 빈도를 기록한다. 또한 profiler에서 변수들의 타입이나 값을 프로파일 했다가, optimizing JIT를 적용할때 이러한 정보를 사용하여 예전 JIT에서 생성했던 예외처리 루틴들을 대폭 생략한 효율적인 코드를 생성하게 된다.
다만 이렇게 코드를 생성할 경우 불리한 상황이 발생할 수 있다. 루프를 100만번 수행하는 동안 한 변수가 int였다가, 다음 반복에서는 string으로 변할 수 있다. 이런 경우에는 optimizing JIT로 생성된 코드는 더 이상 유효하지 않기 때문에 다시 예전 baseline-JITC로 생성된 코드로 수행하게 된다.
이러한 예외 상황이 발생하면 오버헤드가 엄청나게 커지지만, 프로파일링을 수행하는 동안 특정 변수의 타입이 변하지 않았다면 그 이후에도 이 변수는 타입이 변하지 않을 가능성이 매우 높을 것이다 라는 가정을 바탕에 두고 최적화를 수행한 것이다.
(따라서, JavaScript 코드를 작성할때 JavaScript를 정적타입언어라고 가정하고 작성하는게 좋다. 특히 JavaScript 배열에는 다양한 타입의 element를 넣어줄 수 있지만, 한 타입만 넣어주는것이 좋다)
실제로 JavaScript 엔진에서 수행하는 많은 최적화들 (히든클래스, 인라인 캐싱 등)은 이러한 방식으로 최적화를 많이 수행한다. 변수의 타입이나 객체의 프로퍼티가 바뀌는 동적인 변화가 자주 일어나지 않을 것이라고 가정한다. 동적인 변화가 발생했을때의 오버헤드가 크더라도, 변화하지 않았을때의 성능 이득을 볼 수 있는 최적화 방법들을 사용하는 것이다.

정리하자면, hotspot이 많은 코드의 경우 JIT를 사용하면 재사용의 이점때문에 성능이 향상되지만, hotspot이 적은 코드의 경우 오히려 native code를 생성하는 오버헤드가 커��지므로 인터프리터 방식보다 낫다고 할 수 없다. 따라서 JavaScript 엔진은 두가지를 적절히 사용하는 adaptive 컴파일 방식을 사용한다. 기본적으로는 인터프리터를 이용하여 코드를 해석하며, 이때 반복이 많이 되는 부분은 JIT로 최적화를 수행하게 된다. 위의 사진에서 Ignition이 인터프리터, TurboFan이 JIT 컴파일러에 해당한다.